
As organizations evolve from experimental AI workloads to robust production services, they encounter a significant utilization gap in their infrastructure. Typically, enterprises must choose between optimizing for high-concurrency, low-latency real-time requests or focusing on high-throughput async processing.
In Kubernetes environments, these demands are often met by separate GPU and TPU accelerator clusters. This separation can lead to over-provisioning for real-time traffic, resulting in wasted resources during off-peak hours, while async tasks are often managed in isolated clusters, complicating resource management.
Google Kubernetes Engine (GKE) addresses this challenge with the GKE Inference Gateway, offering a unified platform that accommodates various inference patterns. This open-source-first approach allows for a flexible resource pool that can efficiently handle both latency-sensitive and high-throughput workloads.
Understanding Inference Patterns
This discussion focuses on two key types of inference workloads: real-time and async. Real-time inference involves high-priority, synchronous requests, such as chatbot interactions requiring immediate responses. In contrast, async traffic, like document indexing or product categorization, is more tolerant of latency, often allowing for queued processing.
1. Real-Time Inference
For real-time inference, where latency is paramount, traditional load balancing often overlooks critical metrics like KV cache utilization, leading to performance issues.
Solution: GKE Inference Gateway
The Inference Gateway addresses this by employing latency-aware scheduling that predicts server performance based on real-time metrics, effectively minimizing delays and ensuring consistent performance even under heavy loads.
2. Async Inference
Async tasks typically operate under minute-scale service-level objectives rather than millisecond requirements. Traditional setups often isolate these tasks on separate infrastructures to avoid contention with real-time traffic, which can lead to inefficient resource utilization and increased costs.
Solution: Async Processor Agent + Inference Gateway
This architecture integrates the Inference Gateway with Cloud Pub/Sub, where a Batch Processing Agent routes requests as "sheddable" traffic. This allows the system to utilize idle accelerator capacity, reducing fragmentation and costs.
Key Features:
- Real-Time Traffic Support: Managed through Inference Gateway.
- Persistent Messaging: Reliable handling via Pub/Sub.
- Intelligent Retries: Configurable retry logic based on queue monitoring.
- Strict Priority: Real-time requests take precedence over async traffic.
- Tight Integration: Easy routing with a simple Pub/Sub topic setup.

Figure 1: High-level architecture for managing real-time and async inference traffic.
The request flow is as follows:
- Users submit real-time requests, prioritized by the Inference Gateway.
- Async requests can be published via a configured Pub/Sub Topic.
- The Async Processor reads from the queue based on capacity.
- Requests are routed through the Inference Gateway, utilizing shared accelerators.
- Responses are written to an output Topic for users to access.
This consolidation of workloads onto shared accelerators resolves the "cost vs. performance" dilemma, eliminating the need for separate, underutilized clusters and simplifying management.
Real-World Performance
While the theory of combining real-time and async workloads on shared infrastructure is compelling, practical performance is crucial. Initial analyses showed that during peak times, maintaining low-latency responses requires full capacity allocation for real-time traffic, while async tasks should wait for available resources.
Testing revealed that without the Async Processor, resource contention caused a 99% message drop for low-priority requests. However, with the Async Processor, all latency-tolerant requests were successfully processed during available cycles.
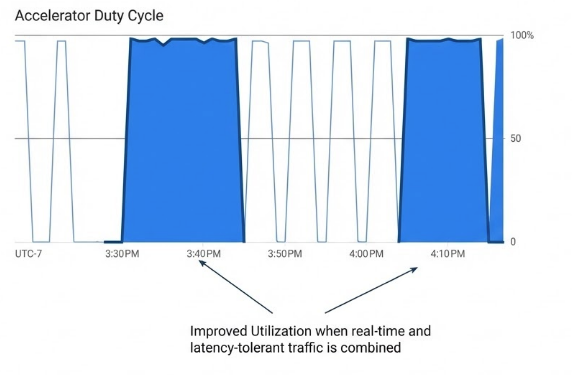
Figure 2: Improved utilization for combined real-time and batch traffic.
Next Steps
If you're interested in deploying both real-time and batch workloads on a unified infrastructure, refer to the Quickstart Guide for Async Inference with Inference Gateway. Contributions to the project are welcome through the OSS Project on GitHub. Future developments will focus on deadline-aware scheduling, enabling users to set flexible batch completion windows and further enhancing system efficiency.






